株価の割安さや収益性をはかる指標としてPER,PBR,ROEは非常に重要だと思います。ただ、これら指標の過去データの取得方法についてあまり情報が見つかりませんでした。無いなら自分で導こうということで、試行錯誤してみたのでブログにまとめます。
1.各種指標について
指標に関する説明は簡単に整理しますが、詳しくは色んなサイトで解説されています。
① PER(Price Earning Ratio):株価収益率

② PBR(Price Book-value Ratio):株価純資産倍率

③ ROE(Return On Equity):自己資本利益率
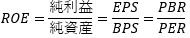
2.データ取得元:J-Quants
J-QuantsはJPX(日本取引所グループ)が個人投資家向けに運営するAPIデータ配信サービスです。API経由で最新の正確な金融データが簡単に取得できるおすすめのサービスですが、いくつか注意点があります。
- 用途が個人の私的利用に限定されているのでデータの第三者配信やデータを利用したアプリの提供などが禁止されている。
- 無償プラン、有償プランがあるが、ちゃんと分析しようとすると確実に有償プランが必要になる。
詳しくはJ-Quantsサイトを参照ください。
jpx-jquants.com
3.J-Quantsからのデータ取得方法
まずは上記J-Quantsサイトでアカウントを作成します。アカウント作成時にメールアドレスとパスワードを登録するのですが、それは後程API呼び出し時にも使います。
その後、プランを選択します。お試しで使いたい場合は無料プランで登録しましょう。

ここまで来たら準備完了です。PythonからAPIを呼び出せます。金融データを呼び出すためにはまずはIDトークンが必要になります。IDトークンはアカウント作成時に登録したメールアドレスとパスワードが必要になります。
import requests
import json
data={"mailaddress":"<YOUR EMAIL_ADDRESS>", "password":"<YOUR PASSWORD>"}
r_post = requests.post("https://api.jquants.com/v1/token/auth_user", data=json.dumps(data))
REFRESH_TOKEN = r_post.json()['refreshToken']
r_post = requests.post(f"https://api.jquants.com/v1/token/auth_refresh?refreshtoken={REFRESH_TOKEN}")
idToken = r_post.json()['idToken']
次に金融データを呼び出します。金融データの種類によって呼び出すAPIは異なります。例えば「株価四本値」の場合は"https://api.jquants.com/v1/prices/daily_quotes"です。以下は2024/4/1~5/1の任天堂の株価四本値を取得してpandas.DataFrameに格納する例です。
import pandas as pd
headers = {'Authorization': 'Bearer {}'.format(idToken)}
params = {'code': '79740', 'from':'20240401', 'to':'20240501'}
r = requests.get("https://api.jquants.com/v1/prices/daily_quotes",params=params, headers=headers)
df = pd.DataFrame(r.json()['daily_quotes'])
上記のcodeの部分は基本的に4桁の銘柄コードに”0”を末尾に付けたものですが、正確な情報は上場銘柄一覧のAPIを呼び出すことで確認することが可能です。
4.データ取得とPER,PBR,ROEの計算
PER,PBR,ROEを計算する場合は、株価四本値と財務情報のAPIが必要になります。財務情報APIでEPSとBPSを取得、株価四本値APIで株価を取得してそれらを計算することでPER,PBR,ROEを計算します。
import pandas as pd
headers = {'Authorization': 'Bearer {}'.format(idToken)}
params = {'code': '79740'}
r = requests.get("https://api.jquants.com/v1/prices/daily_quotes",params=params, headers=headers)
df_quotes = pd.DataFrame(r.json()['daily_quotes'])
r = requests.get("https://api.jquants.com/v1/fins/statements", params=params, headers=headers)
df_statements = pd.DataFrame(r.json()['statements'])
EPSは現在値と会社予想値がありますが、将来予測を目的としているため、会社予想値を採用したいと思います。該当する変数は「ForecastEarningsPerShare」です。ただ、データを見ていただければ分かると思いますが、欠損値があります。これは年度末のデータに見られる傾向で、年度末時点でEPSは確定しているため発生しているものと思われます。そのため、欠損値は次年度のEPS「NextYearForecastEarningsPerShare」で補完します。そのうえで、株価データと突合してPERとPBRを計算します。
def replace_null(df, col):
df.loc[df[col]=='', col] = None
df[col] = df[col].fillna(method='ffill')
return df
df_statements .loc[df_statements ['ForecastEarningsPerShare']=='', 'CurrentFiscalYearEndDate'] = df_statements ['NextFiscalYearEndDate']
df_statements .loc[df_statements ['ForecastEarningsPerShare']=='', 'ForecastEarningsPerShare'] = df_statements ['NextYearForecastEarningsPerShare']
df_statements = replace_null(df_statements , 'BookValuePerShare')
df_statements = replace_null(df_statements , 'NextFiscalYearStartDate')
df_statements = replace_null(df_statements , 'ForecastEarningsPerShare')
df_statements = replace_null(df_statements , 'BookValuePerShare')
df_statements ['ForecastEarningsPerShare'] = df_statements ['ForecastEarningsPerShare'].astype(float)
df_statements ['BookValuePerShare'] = df_statements ['BookValuePerShare'].astype(float)
df_adj = df_quotes[~(df_quotes['AdjustmentFactor']==1)].copy()
for index, row in df_adj.iterrows():
adj_date = row['Date']
adj_factor = row['AdjustmentFactor']
df_stats.loc[df_stats['CurrentFiscalYearEndDate']<adj_date, 'ForecastEarningsPerShare'] = df_stats['ForecastEarningsPerShare']*adj_factor
df_stats.loc[df_stats['NextFiscalYearStartDate']<adj_date, 'BookValuePerShare'] = df_stats['BookValuePerShare']*adj_factor
df_stats = df_stats.loc[~(df_stats.duplicated(subset=['DisclosedDate'], keep='last'))]
df= df_quotes.merge(df_statements , how='left', left_on='Date', right_on='DisclosedDate')
df['ForecastEarningsPerShare'] = df['ForecastEarningsPerShare'].fillna(method='ffill')
df['BookValuePerShare'] = df['BookValuePerShare'].fillna(method='ffill')
df['DisclosedDate'] = df['DisclosedDate'].fillna(method='ffill')
df['per'] = df['AdjustmentClose'] / df['ForecastEarningsPerShare']
df['pbr'] = df['AdjustmentClose'] / df['BookValuePerShare']
df['roe'] = df['pbr'] / df['per']