SHAPを使用した回帰問題の機械学習モデルの局所解釈方法
shapライブラリを使用して、回帰問題を解いた機械学習モデルの大局的解釈を行う。
1.SHAPとは
SHAP(SHapley Additive exPlanations)は、機械学習モデルの局所的な解釈可能性を提供するためのフレームワークです。SHAPは、個々の特徴量が予測にどのように寄与しているかを計算することにより、モデルの解釈性を高めます。
2.データセット
今回はsklearnのdiabetes(糖尿病)データセットを例に実装してみる。データセットの概要は以下の通り。
- 目的変数:1年後の糖尿病の進行に関する測定値
- 説明変数:11個の特徴量
| 特徴量 | 説明 |
|---|---|
| age | 患者の年齢 |
| sex | 患者の性別 |
| bmi | 患者のBMI |
| bp | 患者の平均血圧 |
| S1 | T-Cells (白血球の1種)の活性化に関与する化学物質 |
| S2 | インスリンのレセプターの活性に関与する化学物質 |
| S3 | グルコースの代謝に関与する化学物質 |
| S4 | トリグリセリド (脂質の一種)の代謝に関与する化学物質 |
| S5 | 血清アルブミン (タンパク質の一種)のレベル |
| S6 | 銅の輸送に関与する化学物質 |
※S1~S6: 血清の6つの化学指標。
3.実装
3.1.Lightgbmを用いた簡易的なモデルを作成
from sklearn.datasets import load_diabetes from sklearn.model_selection import train_test_split import lightgbm as lgb import pandas as pd import shap # データのロード diabetes = load_diabetes() x_train, x_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, test_size=0.3) # LightGBMモデルのトレーニング model = lgb.LGBMRegressor().fit(x_train, y_train)
3.2.SHAPの実装
# SHAP値の計算 df_x_test = pd.DataFrame(x_test, columns=diabetes.feature_names) explainer = shap.Explainer(model.predict, df_x_test) shap_values = explainer(df_x_test) # 特定のサンプルのSHAP値を表示(shap_values[x]:x番目のデータのSHAP値を表示、max_display=n:n個の特徴量を描画) shap.plots.waterfall(shap_values[0], max_display=10)
上記の結果、以下のような図が表示されます。

E[f(x)]は、モデルの期待出力値(期待値)を表しています。つまり、全体的な平均予測値です。 SHAP値は、個々の特徴量がこの期待値からどれだけ上下に影響を与えたかを表します。
PDP/ICEを使用した回帰問題の機械学習モデルの大局的解釈方法
pdpboxライブラリを使用して、回帰問題を解いた機械学習モデルの大局的解釈を行う。
1.データセット
今回はsklearnのボストン住宅価格データセットを例に実装してみる。データセットの概要は以下の通り。
- 目的変数:ボストンの地域別住宅価格
- 説明変数:以下13個の特徴量1
| 特徴の名前 | 説明 |
|---|---|
| CRIM | 人口 1 人当たりの犯罪発生数 |
| ZN | 25,000 平方フィート以上の住居区画の占める割合=「広い家の割合」 |
| INDUS | 小売業以外の商業が占める面積の割合 |
| CHAS | チャールズ川に関わるダミー変数 (1: 川の周辺, 0: それ以外) |
| NOX | 一酸化窒素の濃度 |
| RM | 住居の平均部屋数 |
| AGE | 1940 年より前に建てられた物件の割合 =「古い家の割合」 |
| DIS | ボストン市の5 つの雇用施設からの距離 (重み付け済) =「主要施設への距離」 |
| RAD | 高速道路へのアクセスのしやすさ |
| TAX | $10,000 ドルあたりの固定資産税率 |
| PTRATIO | 町毎の生徒と教師の比率 |
| B | 町毎の黒人 (Bk) の比率 |
| LSTAT | 低所得者人口の割合 |
2.実装
2.1.Lightgbmを用いた簡易的なモデルを作成
from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split import pandas as pd import lightgbm as lgb boston = load_boston() x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.3) #LGB用のデータに変形 lgb_train = lgb.Dataset(x_train, y_train) lgb_eval = lgb.Dataset(x_test, y_test) params = { 'objective': 'regression', 'boosting_type': 'gbdt', 'metric': 'mae' } model = lgb.train( params = params, train_set = lgb_train, valid_sets= [lgb_eval,lgb_train], )
2.2.PDP/ICEの実装
# pdpboxはpandas.DataFrameしか受け付けない test_df = pd.DataFrame(x_test, columns=boston.feature_names) # 特徴量毎にpdp/iceを描画 for col in train_df.columns: pdp_boston = pdp.pdp_isolate( model=model, dataset=test_df, model_features=test_df.columns, feature=col ) fig, axes = pdp.pdp_plot(pdp_boston, col, plot_lines=True, frac_to_plot=1.0, plot_pts_dist=True)
特徴量毎に以下のような図が描画される。

上図より、一酸化窒素の濃度が0.7までは住宅価格にあまり影響がなく、0.7以上あたりから住宅価格を下げる要因と機械学習モデルが判断していることが分かる。
2.3.PDP(2変数)の実装
ついでに2変数の相互作用を等高線として図示する方法もまとめておく。
import itertools columns = test_df.columns combinations = itertools.combinations(columns, 2) for combination in combinations: interaction = pdp.pdp_interact(model=model, dataset=test_df, model_features=test_df.columns, features=combination) fig, axes = pdp.pdp_interact_plot(pdp_interact_out=interaction, feature_names=combination)
特徴量の組み合わせ毎に以下のような図が描画される。

上図より、固定資産税率が350を超えたあたりから住宅価格にあまり影響がなく、犯罪発生率の方が影響していることが分かる。
- ボストンデータセットの特徴量の説明:【初心者】ネコでも分かる「scikit-learnのサンプルデータ」まとめ【Python】を引用↩
Tensorflow-EfficientnetでGradCAMを実装してみた
前々から気になってたGrad-CAMを実装してみました。実装に当たって以下を参考としてます。
EfficientNet-Keras-GradCam-Visualization/inference_example.ipynb at master · lvisdd/EfficientNet-Keras-GradCam-Visualization · GitHub
上記は訓練済みのEfficientnetモデルをそのまま使っているのですが、この記事ではFinetuneもしてみました。Efficientnetは以下を使用しています。
GitHub - qubvel/efficientnet: Implementation of EfficientNet model. Keras and TensorFlow Keras.
1.個人的に引っかかったポイント
私はよく以下のようにEfficientnetのモデルを作成するのですが、以下の方法だとGrad-CAMで最終レイヤーを取得できず失敗するようです。
from efficientnet.tfkeras import EfficientNetB0 model = Sequential() model.add(EfficientNetB0( include_top=False, weights='imagenet', input_shape=input_shape)) model.add(GlobalAveragePooling2D()) model.add(Dense(num_classes, activation="softmax"))
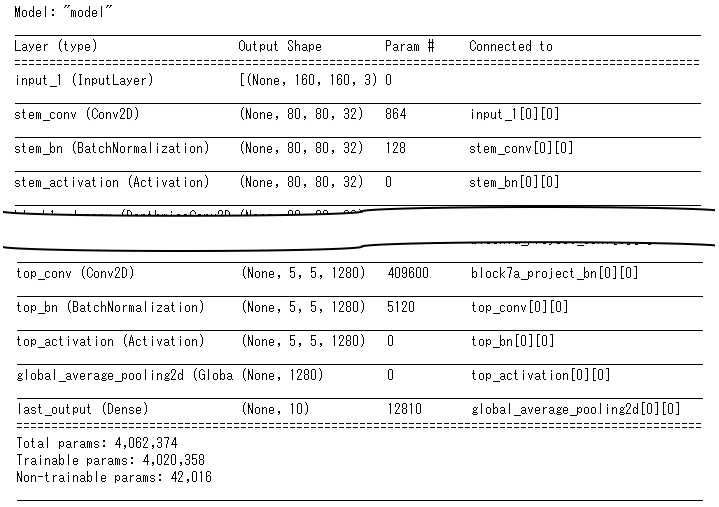
上記でモデルを作成して、model.summary()を実行すると以下の通りとなります。efficientnet-b0レイヤーとしてまとまってしまうのが問題なんだと思います

代わりに以下の通りモデルを作成することでうまくいきました。
from efficientnet.tfkeras import EfficientNetB0 eff = EfficientNetB0( include_top=False, weights='imagenet', input_shape=input_shape) x = tf.keras.layers.GlobalAveragePooling2D()(eff.output) output = tf.keras.layers.Dense(num_classes, activation='softmax', name='last_output')(x) model = tf.keras.Model(inputs=eff.inputs, outputs=output, name='model')
model.summary()の実行結果は以下の通りです。長いので途中省略してますが、要は上記でモデルを作成すると、Efficientnet内部のレイヤーが残るようです。
2.Grad-CAMの実装
先述の通り、Grad-CAMの実装に当たってはこちらを参考としていますが、参考サイトではKerasを使用しており、Tensorflow.Kerasを使用している場合、エラーとなるので、多少修正しました。最終版は以下の通りです。tensorflow==2.3.0では問題なく動きました。
# grad cam関数 def grad_cam(input_model, image, cls, layer_name): """GradCAM method for visualizing input saliency.""" y_c = input_model.output[0, cls] conv_output = input_model.get_layer(layer_name).output g = tf.Graph() with g.as_default(): grads = tf.gradients(y_c, conv_output)[0] # Normalize if necessary # grads = normalize(grads) gradient_function = K.function([input_model.input], [conv_output, grads]) output, grads_val = gradient_function([image]) output, grads_val = output[0, :], grads_val[0, :, :, :] weights = np.mean(grads_val, axis=(0, 1)) cam = np.dot(output, weights) # Process CAM cam = cv2.resize(cam, (image_size, image_size), cv2.INTER_LINEAR) cam = np.maximum(cam, 0) cam = cam / cam.max() return cam
3.CIFAR10で試してみた
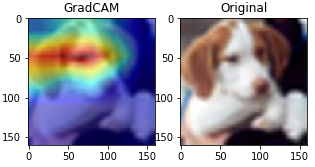
EfficientnetのモデルをCIFAR10でFinetuneし、Grad-CAMを適用してみました。結果は以下の通りです。無事、注視範囲の可視化に成功しました。目と耳に反応しているんですかね?
参考:ソースコード全文
データセット:CIFAR10
使用モデル:Efficientnet-v1-b0
#ライブラリインポート import tensorflow as tf import numpy as np import pandas as pd import matplotlib.pyplot as plt from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, GlobalAveragePooling2D, Flatten from tensorflow.keras.utils import to_categorical from tensorflow.keras.preprocessing.image import ImageDataGenerator from efficientnet.tfkeras import EfficientNetB0 from tensorflow.keras import optimizers from tensorflow.keras.callbacks import ReduceLROnPlateau, EarlyStopping from sklearn.model_selection import train_test_split from tensorflow.keras.datasets import cifar10 import datetime from tensorflow.keras import backend as K import cv2 # 画像をリサイズ(拡大)する関数を定義 def upscale(image): size = len(image) data_upscaled = np.zeros((size, RESIZE_TO, RESIZE_TO, 3,)) for i in range(len(image)): data_upscaled[i] = cv2.resize(image[i], dsize=(RESIZE_TO, RESIZE_TO), interpolation=cv2.INTER_CUBIC) image = np.array(data_upscaled, dtype='uint8') return image # データインポート (x_train, y_train), (x_test, y_test) = cifar10.load_data() # 画像リサイズ IMAGE_SIZE = 32 RESIZE_TO = 160 x_train = upscale(x_train) x_test = upscale(x_test) # 変数定義 image_size = RESIZE_TO input_shape=(image_size,image_size,3) # 予測するクラスの数 num_classes = 10 # モデル定義 def build_model(): eff = EfficientNetB0( include_top=False, weights='imagenet', input_shape=input_shape) x = tf.keras.layers.GlobalAveragePooling2D()(eff.output) output = tf.keras.layers.Dense(num_classes, activation='softmax', name='last_output')(x) model = tf.keras.Model(inputs=eff.inputs, outputs=output, name='model') model.compile(optimizer=optimizers.Adam(learning_rate=1e-4), loss="categorical_crossentropy", metrics=["accuracy"]) return model # 訓練用関数の定義 def train_model(X, y, epochs, batch_size, callbacks): # 訓練データと評価データの分割 X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, stratify=y, shuffle=True) y_train = to_categorical(y_train) y_valid = to_categorical(y_valid) # Data Augumentation datagen = ImageDataGenerator( rotation_range=20, horizontal_flip=True, width_shift_range=0.2, zoom_range=0.2, ) #モデル構築 model = build_model() # 学習 model.fit( datagen.flow(X_train, y_train, batch_size=batch_size), validation_data=(X_valid, y_valid), steps_per_epoch=len(X_train) / batch_size, epochs=epochs, callbacks=callbacks, shuffle=True ) return model # 訓練実施 epochs = 3 batch_size = 32 reduce_lr = ReduceLROnPlateau( monitor='val_accuracy', factor=0.2, patience=1, verbose=1, min_delta=1e-4, min_lr=1e-6, mode='max' ) earlystopping = EarlyStopping( monitor='val_accuracy', min_delta=1e-4, patience=2, mode='max', verbose=1 ) callbacks = [earlystopping, reduce_lr] print('開始時間:',datetime.datetime.now()) model = train_model(x_train, y_train, epochs, batch_size, callbacks) print('終了時間:',datetime.datetime.now()) # 予測 preds = [] X = x_test pred = model.predict(X) # 予測結果の確認 df_pred = pd.DataFrame(pred) pred = np.array(df_pred.idxmax(axis=1)) df_pred = pd.DataFrame(pred) df_y = pd.DataFrame(y_test) df_result = pd.concat([df_y, df_pred], axis=1, join_axes=[df_y.index]) df_result.columns = ['y','pred'] from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix print('Confusion Matrix:') print(confusion_matrix(df_result['y'],df_result['pred'])) print() print('Accuracy :{:.4f}'.format(accuracy_score(df_result['y'],df_result['pred']))) print('Precision:{:.4f}'.format(precision_score(df_result['y'],df_result['pred'],average='macro'))) print('Recall :{:.4f}'.format(recall_score(df_result['y'],df_result['pred'],average='macro'))) print('F_score :{:.4f}'.format(f1_score(df_result['y'],df_result['pred'],average='macro'))) # grad cam関数 def grad_cam(input_model, image, cls, layer_name): """GradCAM method for visualizing input saliency.""" y_c = input_model.output[0, cls] conv_output = input_model.get_layer(layer_name).output g = tf.Graph() with g.as_default(): grads = tf.gradients(y_c, conv_output)[0] # Normalize if necessary # grads = normalize(grads) gradient_function = K.function([input_model.input], [conv_output, grads]) output, grads_val = gradient_function([image]) output, grads_val = output[0, :], grads_val[0, :, :, :] weights = np.mean(grads_val, axis=(0, 1)) cam = np.dot(output, weights) # Process CAM cam = cv2.resize(cam, (image_size, image_size), cv2.INTER_LINEAR) cam = np.maximum(cam, 0) cam = cam / cam.max() return cam # modelの確認 model.summary() # cifar10 class labels labels = { 0:"airplane", 1:"automobile", 2:"bird", 3:"cat", 4:"deer", 5:"dog", 6:"frog", 7:"horse", 8:"ship", 9:"truck" } # grad cam n = 16 #n番目の画像に対してGradCAM適用する preprocessed_input = x_test[n:n+1].copy() predictions = model.predict(preprocessed_input) cls = np.argmax(predictions) layer_name='top_activation' gradcam = grad_cam(model, preprocessed_input, cls, layer_name) # visualise grad cam print("TRUE : {}".format(labels[y_test[n,0]])) print("PRED : {}".format(labels[cls])) for i in range(num_classes): print(" {:<10s} : {:5.2f}%".format(labels[i],predictions[0,i]*100)) plt.figure(figsize=(5, 5)) plt.subplot(121) plt.title('GradCAM') plt.imshow(preprocessed_input[0]) plt.imshow(gradcam, cmap='jet', alpha=0.5) plt.subplot(122) plt.title('Original') plt.imshow(preprocessed_input[0]) plt.show()
ImageDataGeneratorでデータ拡張してみた
ImageDataGeneratorを使って画像拡張を色々試してみます。使う画像は実家のワンコ(小次郎君)の写真です。

1.画像の水増し
① 回転(rotation_range)
datagen = ImageDataGenerator(
rotation_range=90,
)
g = datagen.flow(x, batch_size=x.shape[0], shuffle=False)
itr=3
generated_imgs = []
for i in range(itr):
generated_img = g.next()
generated_imgs.extend(generated_img)
- 入力画像はx。x.shape=(1, 1478, 1108, 3)=(画像1枚、縦幅1478ピクセル、横幅1108ピクセル、カラー画像)。
- 出力画像はgenerated_imgs。generated_imgs.shape=(3, 1478, 1108, 3)=(画像3枚、縦幅1478ピクセル、横幅1108ピクセル、カラー画像)。
拡張された画像を確認します。
generated_imgs = np.array(generated_imgs) fig = plt.figure(figsize=(15,5)) fig.add_subplot(1,itr+1,1) plt.title("original img") plt.imshow(x[0]) for i,img in enumerate(generated_imgs): fig.add_subplot(1,itr+1,i+2) plt.title("aug img {}".format(i)) plt.imshow(img) plt.show()

② 横にずらす(width_shift_range)
datagen = ImageDataGenerator(
width_shift_range=0.5,
)

※コードは 「① 回転」とほぼ同じなので重複分は省略。
③ 縦にずらす(height_shift_range)
datagen = ImageDataGenerator(
height_shift_range=0.5,
)

※コードは 「① 回転」とほぼ同じなので重複分は省略。
④ 明るさを変える(brightness_range)
datagen = ImageDataGenerator(
brightness_range=[0.5,1.5],
)

※コードは 「① 回転」とほぼ同じなので重複分は省略。


⑦ RGB各チャネルに0~指定した値をランダムに加算または減算(channel_shift_range)
datagen = ImageDataGenerator(
channel_shift_range=100,
)

※コードは 「① 回転」とほぼ同じなので重複分は省略。
⑧ 水平方向に反転(horizontal_flip)
datagen = ImageDataGenerator(
horizontal_flip=True,
)

※コードは 「① 回転」とほぼ同じなので重複分は省略。
⑨ 垂直方向に反転(vertical_flip)
datagen = ImageDataGenerator(
vertical_flip=True,
)

※コードは 「① 回転」とほぼ同じなので重複分は省略。
参考:余白の埋め方(fill_mode, cval)
画像のずらしたりするときに、画像に余白ができることがあります。その処理の仕方が複数用意されているので、それぞれ試してみます。cvalの値によって、塗りつぶしの色が変わります。色は白(0)~黒(255)です。
① constant, cval
余白を単色で塗りつぶす。
datagen = ImageDataGenerator(
width_shift_range=0.5,
fill_mode='constant',
cval=0.0, #ココの値で色を変える
)



※コードは 「① 回転」とほぼ同じなので重複分は省略。
② nearest
隣接しているピクセルの色をコピーして余白を埋めます。ちなみにfill_modeのデフォルトはnearestです。
datagen = ImageDataGenerator(
width_shift_range=0.5,
fill_mode='nearest',
)

※コードは 「① 回転」とほぼ同じなので重複分は省略。
③ reflect
画像を反転させて余白を埋めます。
datagen = ImageDataGenerator(
width_shift_range=0.5,
fill_mode='reflect',
)

※コードは 「① 回転」とほぼ同じなので重複分は省略。
④ wrap
画像を複製して余白を埋めます。
datagen = ImageDataGenerator(
width_shift_range=0.5,
fill_mode='wrap',
)

※コードは 「① 回転」とほぼ同じなので重複分は省略。
2.正規化
2.1.画像単位に正規化
① 平均を0にする(samplewise_center)
datagen = ImageDataGenerator(
samplewise_center=True,
)
画像のデータの平均が0になるように正規化します。以下を見てもらえれば分かると思いますが、全データに対して平均値を減算しています。


2.2.データセット単位に正規化
① 平均を0にする(featurewise_center)
実装する上での注意点ですが、データセット単位に正規化する場合はImageDataGenerator.fit()を呼び出す必要があります。fit()でデータセット全体の統計量を計算しているようです。
datagen = ImageDataGenerator(
featurewise_center=True,
)
datagen.fit(x)
g = datagen.flow(x, batch_size=x.shape[0], shuffle=False)
画像のデータをデータセット全体の平均値で正規化します。イメージは以下の通りです。samplewizseのときはチャネル関係なく全データの平均を使って平均していましたが、featurewiseの方はチャネル毎に平均を取って正規化しているようです。何故そのような仕様になっているのかは分からないです。分かる方いらっしゃったらコメントいただけると嬉しいです。

※上記の数式はあくまでイメージです。雑な表現ではありますが、ご容赦ください。
※微妙に計算合わないですが、端数処理ですかね…?
② 標準偏差で正規化(featurewise_std_normalization)
datagen = ImageDataGenerator(
featurewise_std_normalization=True,
)
datagen.fit(x)
g = datagen.flow(x, batch_size=x.shape[0], shuffle=False)
こちらもチャネル毎に正規化しているようです。イメージは以下の通り。

※こちらも雑な表現ご容赦ください。
※同じく、微妙に計算が合わない。
③ ZCA白色化(zca_whitening)
ZCA白色化は大量にメモリを食うようです。1280×960の画像でZCA白色化を実施しようとしたところ、メモリ49.4TiB必要だって怒られました。しょうがないので、めちゃめちゃ画像を縮小させました。
datagen = ImageDataGenerator(
zca_whitening=True,
zca_epsilon=1e-06,
)
datagen.fit(x)
g = datagen.flow(x, batch_size=x.shape[0], shuffle=False)
共分散行列が単位行列になるように変換しているようです。ZCAイプシロンがどう使われていて、どのような影響を及ぼすのかは正直分からないです。ZCAイプシロンをデフォルトの1e-06としたときに以下のように画像データが変換されていました。

機械学習における不均衡データへの対処方法(Over Sampling, Under Sampling)
機械学習における不均衡データへの対処方法としてアンダーサンプリングやオーバーサンプリングについてまとめます。不均衡データとは目的変数のクラスの度数が極端に偏っているデータのことです。今回はKaggleで公開されている「Credit Card Fraud Detection」のデータセットを使用して以下の手法を試してみます。
- Random Under Sampling
- Random Over Sampling
- SMOTE
「Credit Card Fraud Detection」の目的変数の各クラスの度数は以下の通り。偏りが発生していることが分かります。

1.何も対策せずに機械学習させるとどうなるか
試しに適当なニューラルネットワークを構築して試してみました。構築したニューラルネットワークは以下の通り。コード全文は本稿末尾にまとめました。
from tensorflow.keras.callbacks import EarlyStopping from tensorflow.keras.models import Sequential from tensorflow.keras.layers import InputLayer, Dense, Activation, Dropout from tensorflow.keras.optimizers import Adam def train_dnn(new_nx_train,new_t_train): model = Sequential() model.add(InputLayer(input_shape=new_nx_train[1].shape)) model.add(Dense(8)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(8)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(1)) model.add(Activation('sigmoid')) callbacks = EarlyStopping(monitor='val_loss', patience=3, mode='auto') # モデルのコンパイル model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 学習 ep=100 model.fit(new_nx_train, new_t_train, epochs=ep, batch_size=126, validation_split=0.3, verbose=2, callbacks=callbacks) return model
上記で学習させた結果は以下の通り。ちなみに学習データ70%、テストデータ30%に分割して、テストデータに対して予測した結果です。

全部0と予測してしまっています。
2.不均衡データの均衡化
2.1.Random Under Sampling
少数派のクラスに合わせて、多数派のクラスのデータをランダムに削除する手法です。imblearn.under_sampling.RandomUnderSamplerを使用することで、簡単に実装できます。
from imblearn.under_sampling import RandomUnderSampler # 少数派クラスのデータ数をカウント positive_count_train = y_train["Class"].value_counts()[1] # Random under sampling rus = RandomUnderSampler(sampling_strategy={0:np.round(positive_count_train * 9).astype(int), 1:positive_count_train}, random_state=0) X_train_undersampled, y_train_undersampled = rus.fit_resample(X_train, y_train)
上記を実行することで、以下の通り多数派クラスのデータが減ります。

上記のデータを使って1.で構築したニューラルネットワークを学習させました。結果は以下の通り。予測精度が向上していることが分かります。

2.2.Random Over Sampling
多数派のクラスに合わせて少数派のクラスのデータをランダムに複製する手法です。imblearn.over_sampling.RandomOverSamplerを使います。
from imblearn.over_sampling import RandomOverSampler # 多数派クラスのデータ数をカウント negative_count_train = y_train["Class"].value_counts()[0] # Random over sampling ros = RandomOverSampler(sampling_strategy={0: negative_count_train, 1: negative_count_train//9}, random_state=0) X_train_oversampled, y_train_oversampled = ros.fit_resample(X_train, y_train)
以下の通り少数派クラスのデータが増えます。

上記のデータを学習させてみたところ、予測精度は以下の通りとなりました。Random Under Samplingの方が若干精度が良かったですが、何もしないよりはかなり良い結果となりました。

2.3.SMOTE
SMOTEとは元のデータから類似するデータを生成する手法で、以下の手順を繰り返すことでデータを生成します。
- 元データからランダムにデータを選択
- 選択したデータの近傍に存在するデータからランダムに1つを選択
- 選択したデータと近傍データの間に新たなデータを生成

imblearn.over_sampling.SMOTEを使って実装できます。
from imblearn.over_sampling import SMOTE # 多数派クラスのデータ数をカウント negative_count_train = y_train["Class"].value_counts()[0] # SMOTE smote = SMOTE(sampling_strategy={0: negative_count_train, 1: negative_count_train//9}, k_neighbors=5, random_state=0) X_train_smotesampled, y_train_smotesampled = smote.fit_resample(X_train, y_train)
以下の通り少数派クラスのデータが増えます。
上記のデータを学習させてみたところ、予測精度は以下の通りとなりました。こちらもRandom Under Samplingの方が若干精度が良かったですが、何もしないよりはかなり良い結果となりました。

3.その他手法
SMOTEには多数の亜種があるようです。また、Under Samplingの手法も数多く存在します。imblearnには色々な手法が揃っていますので、興味がある人は一度見てみてください。
参考:ソースコード
再現性確保のためのおまじない
# 再現性確保のためのおまじない import os os.environ['PYTHONHASHSEED'] = '0' import tensorflow as tf os.environ['TF_DETERMINISTIC_OPS'] = 'true' os.environ['TF_CUDNN_DETERMINISTIC'] = 'true' import random as rn import numpy as np SEED = 123 def reset_random_seeds(): tf.random.set_seed(SEED) np.random.seed(SEED) rn.seed(SEED) reset_random_seeds() session_conf = tf.compat.v1.ConfigProto(intra_op_parallelism_threads=32, inter_op_parallelism_threads=32) tf.compat.v1.set_random_seed(SEED) sess = tf.compat.v1.Session(graph=tf.compat.v1.get_default_graph(), config=session_conf)
データのインポート
# データのインポート import pandas as pd df = pd.read_csv("./creditcard.csv") *** 各種関数の定義 >|pyhton| # 標準化とNumpy化用の関数 def standard_and_toNumpy(X_train, X_test, y_train): # 平均、標準偏差計算 X_train_mean = X_train.mean() X_train_std = X_train.std() # データの標準化 nx_train_df = (X_train - X_train_mean)/X_train_std nx_test_df = (X_test - X_train_mean)/X_train_std # numpyに変換 nx_train = nx_train_df.values nx_test = nx_test_df.values t_train = y_train.values return nx_train, nx_test, t_train # 学習用データをシャッフルするための関数 ## シャッフルしないと、model.fitのvalidation_split時に目的変数に偏りが発生してしまうため def shuffle_in_unison(a, b): assert len(a) == len(b) shuffled_a = np.empty(a.shape, dtype=a.dtype) shuffled_b = np.empty(b.shape, dtype=b.dtype) permutation = np.random.permutation(len(a)) for old_index, new_index in enumerate(permutation): shuffled_a[new_index] = a[old_index] shuffled_b[new_index] = b[old_index] return shuffled_a, shuffled_b from tensorflow.keras.callbacks import EarlyStopping from tensorflow.keras.models import Sequential from tensorflow.keras.layers import InputLayer, Dense, Activation, Dropout from tensorflow.keras.optimizers import Adam # 訓練用関数 def train_dnn(new_nx_train,new_t_train): model = Sequential() model.add(InputLayer(input_shape=new_nx_train[1].shape)) model.add(Dense(8)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(8)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(1)) model.add(Activation('sigmoid')) callbacks = EarlyStopping(monitor='val_loss', patience=3, mode='auto') # モデルのコンパイル model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 学習 ep=100 model.fit(new_nx_train, new_t_train, epochs=ep, batch_size=126, validation_split=0.3, verbose=2, callbacks=callbacks) return model # 混同行列を見やすくする関数。以下を参考とした。 # https://qiita.com/makaishi2/items/9fb6bf94daa6208c8ed0 def make_cm(matrix, columns): # columns 項目名リスト n = len(columns) # '正解データ'をn回繰り返すリスト生成 act = ['正解データ'] * n pred = ['予測結果'] * n #データフレーム生成 cm = pd.DataFrame(matrix, columns=[pred, columns], index=[act, columns]) return cm from sklearn.metrics import confusion_matrix, precision_score, accuracy_score, recall_score, f1_score # テストデータの予測精度を表示 def show_evaluation_index(y_test,pred): display(make_cm(confusion_matrix(y_test, pred),["0","1"])) print("accuracy_score:{:.5f}".format(accuracy_score(y_test, pred))) print("precision_score:{:.5f}".format(precision_score(y_test, pred))) print("recall_score:{:.5f}".format(recall_score(y_test, pred))) print("f1_score:{:.5f}".format(f1_score(y_test, pred)))
まずはシンプルにニューラルネットワークにデータを突っ込む
# 訓練データとテストデータの分割 from sklearn.model_selection import train_test_split X = df.drop(["Class","Time"], axis=1) y = df[["Class"]] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=100, stratify=y) # 標準化とNumpy化 nx_train, nx_test, t_train = standard_and_toNumpy(X_train, X_test, y_train) # 学習データのシャッフル実施 reset_random_seeds() new_nx_train, new_t_train = shuffle_in_unison(nx_train, t_train) # 訓練 reset_random_seeds() model = train_dnn(new_nx_train,new_t_train) # 予測 y_pred = model.predict(nx_test) y_pred = np.round(y_pred) show_evaluation_index(y_test,y_pred)
Under Sampling
# 少数派クラスのデータ数をカウント positive_count_train = y_train["Class"].value_counts()[1] # Random under sampling rus = RandomUnderSampler(sampling_strategy={0:np.round(positive_count_train * 9).astype(int), 1:positive_count_train}, random_state=0) X_train_undersampled, y_train_undersampled = rus.fit_resample(X_train, y_train) # 標準化とNumpy化 nx_train, nx_test, t_train = standard_and_toNumpy(X_train_undersampled, X_test, y_train_undersampled) # 学習データのシャッフル実施 reset_random_seeds() new_nx_train, new_t_train = shuffle_in_unison(nx_train, t_train) # 訓練 reset_random_seeds() model_undersample = train_dnn(new_nx_train,new_t_train) # 予測 y_pred_undersample = model_undersample.predict(nx_test) y_pred_undersample = np.round(y_pred_undersample) show_evaluation_index(y_test,y_pred_undersample)
Over Sampling
# 多数派クラスのデータ数をカウント negative_count_train = y_train["Class"].value_counts()[0] # Random over sampling ros = RandomOverSampler(sampling_strategy={0: negative_count_train, 1: negative_count_train//9}, random_state=0) X_train_oversampled, y_train_oversampled = ros.fit_resample(X_train, y_train) # 標準化とNumpy化 nx_train, nx_test, t_train = standard_and_toNumpy(X_train_oversampled, X_test, y_train_oversampled) # 学習データのシャッフル実施 reset_random_seeds() new_nx_train, new_t_train = shuffle_in_unison(nx_train, t_train) # 訓練 reset_random_seeds() model_oversample = train_dnn(new_nx_train,new_t_train) # 予測 y_pred_oversample = model_oversample.predict(nx_test) y_pred_oversample = np.round(y_pred_oversample) show_evaluation_index(y_test,y_pred_oversample)
SMOTE
# SMOTE smote = SMOTE(sampling_strategy={0: negative_count_train, 1: negative_count_train//9}, k_neighbors=5, random_state=0) X_train_smotesampled, y_train_smotesampled = smote.fit_resample(X_train, y_train) # 標準化とNumpy化 nx_train, nx_test, t_train = standard_and_toNumpy(X_train_smotesampled, X_test, y_train_smotesampled) # 学習データのシャッフル実施 reset_random_seeds() new_nx_train, new_t_train = shuffle_in_unison(nx_train, t_train) # 訓練 reset_random_seeds() model_smotesample = train_dnn(new_nx_train,new_t_train) # 予測 y_pred_smotesample = model_smotesample.predict(nx_test) y_pred_smotesample = np.round(y_pred_smotesample) show_evaluation_index(y_test,y_pred_smotesample)
LightGBMでOptunaを使用するときの再現性確保について
Optunaとはハイパーパラメータチューニングを自動で実施してくれる大変便利なフレームワークで、LightGBMを使う人は良く使うんじゃないかなと思います。今回はそんなOptunaを使用するときの再現性の確保方法についてまとめます。私が使用しているパッケージのバージョンは以下の通りです。
- lightgbm 2.3.1
- optuna 2.8.0
1.概要
主なポイントは以下です。
- lightgbm.train()ではなく、lightgbm.LightGBMTuner()を使用して訓練する。
- 以下のパラメータを使用する。
- deterministic
- force_row_wiseまたはforce_col_wise
- optuna_seed
- 乱数シードを固定する(numpy.random.seedおよびrandom.seed)。
上記を1つずつ解説します。てっとり早くソース全文を確認したい方は本稿末尾をご参照ください。sklearnのirisデータ(アヤメデータ)を使用したサンプルコードを掲載しています。
2.解説
2.1.訓練用の関数としてLightGBMTunerを使用する
LightGBMを使用するときに、多くの人は以下のような実装をするのではないかな思います。
import optuna.integration.lightgbm as lgb ''' データの前処理等を実施(省略) ''' # 訓練実施 lgb.train(params, lgb_train, lgb_eval)
上記のlightgbm.train()をlightgbm.LightGBMTuner()に変更します。そうすることで、後述するパラメータが使えるようになります。
注意点ですが、lightgbm.LightGBMTuner()を使用すると、訓練の実施やモデルの取得等を明示的に定義する必要があります。実装は以下の通りです。
# 訓練方法の定義 booster = lgb.LightGBMTuner( params = params, train_set = lgb_train, valid_sets=lgb_eval, optuna_seed=123, ) # 訓練の実施 booster.run() # 訓練で得た最良のパラメータを表示 booster.best_params # 訓練で得た最良のモデル(Boosterオブジェクト)を取得する best_booster = booster.get_best_booster()
2.2.再現性確保用のパラメータの使用
以下のようにパラメータを使用します。
params = {
'objective': 'multiclass ',
'num_class':3,
'metric': 'multi_logloss',
'verbosity': -1,
'boosting_type': 'gbdt',
'deterministic':True, #再現性確保用のパラメータ
'force_row_wise':True #再現性確保用のパラメータ
}
booster = lgb.LightGBMTuner(
params = params,
train_set = lgb_train,
valid_sets=lgb_eval,
optuna_seed=123, #再現性確保用のパラメータ
)
2.3.乱数シードの固定
numpy等で使用する乱数シードを固定する。実装は以下の通りです。
import numpy as np import random as rn np.random.seed(123) rn.seed(123)
参考:sklearnのirisデータを使用したサンプルコード
# 乱数シードの固定 import numpy as np import random as rn np.random.seed(123) rn.seed(123) # ライブラリのインポート from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix import pandas as pd from optuna.integration import lightgbm as lgb # iris(アヤメ)データインポート iris = load_iris() # 訓練用データとテストデータに分割 x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3,random_state=123) #LGB用のデータに変形 lgb_train = lgb.Dataset(x_train, y_train) lgb_eval = lgb.Dataset(x_test, y_test) # 訓練方法の定義 params = { 'objective': 'multiclass ', 'num_class':3, 'metric': 'multi_logloss', 'verbosity': -1, 'boosting_type': 'gbdt', 'deterministic':True, #再現性確保用のパラメータ 'force_row_wise':True #再現性確保用のパラメータ } booster = lgb.LightGBMTuner( params = params, train_set = lgb_train, valid_sets=lgb_eval, optuna_seed=123, #再現性確保用のパラメータ ) # 訓練の実施 booster.run() # 訓練で得た最良のパラメータを表示 booster.best_params # 訓練で得た最良のモデル(Boosterオブジェクト)を取得する best_booster = booster.get_best_booster() # テストデータに対して予測を実施 pred = best_booster.predict(x_test) pred = np.argmax(pred, axis=1) # 混同行列(Confusion Matrix)の表示 cm = confusion_matrix(y_test, pred) print(cm)
私の環境では、上記を実行することで、ハイパーパラメータが以下の通り固定されました。もしかしたら、環境によって結果は変わるかもしれませんが、同一環境であれば同一の結果になると思います。

TensorFlowとPytorchにおける画像のデータ構造の違いと変換方法について
本記事では以下についてまとめます。
- TensorFlowとPytorchにおける画像のデータ構造の違いについて解説
- データ構造の相互に変換する方法について解説
1.TensorFlowとPytorchの画像のデータ構造の違い
1.1.概要
画像データは4次元配列で表現され、各次元の要素で以下を表現します。
- バッチ数(画像の枚数)
- 高さ
- 幅
- チャネル(色の成分の数(例:カラー画像はRGBでチャネル数3))
TensorFlowとPytorchで上記の要素の順番が異なります。
- TensorFlowの場合
[バッチ数, 高さ, 幅 , チャネル] - Pytorchの場合
[バッチ数, チャネル, 高さ, 幅]
TensorFlow用の画像のデータ構造は「channel last」と呼び、Pytorch用は「channel first」と呼びます。
1.2.具体例を使ってデータ構造の違いを確認
TensorFlow用の画像
配列の中が見えやすいように、numpyを使って、Tensorflow用の画像を作成してみます。
# 高さ2×幅6のカラー画像(チャネル数3)の4枚を作成 image_channel_last = np.array([ # 1個目の画像 [[[0,255,0],[0,0,255],[255,0,0],[0,255,0],[0,0,255],[255,0,0]], [[255,0,0],[0,255,0],[0,0,255],[255,0,0],[0,255,0],[0,0,255]]], # 2個目の画像 [[[0,255,255],[255,0,255],[255,255,0],[0,255,255],[255,0,255],[255,255,0]], [[255,0,255],[255,255,0],[0,255,255],[255,0,255],[255,255,0],[0,255,255]]], # 3個目の画像 [[[0,0,0],[0,0,0],[0,0,0],[0,0,0],[0,0,0],[0,0,0]], [[255,255,255],[255,255,255],[255,255,255],[255,255,255],[255,255,255],[255,255,255]]], # 4個目の画像 [[[255,255,255],[255,255,255],[255,255,255],[255,255,255],[255,255,255],[255,255,255]], [[0,0,0],[0,0,0],[0,0,0],[0,0,0],[0,0,0],[0,0,0]]], ])
上記をnp.shape関数で各次元の要素数を確認してみると以下の通りとなり、channel lastになっていることが分かります。

Pytorch用の画像
続いてPytorch用の画像の配列を作成してみます。
# 高さ2×幅6のカラー画像(チャネル数3)の4枚を作成 image_channel_first = np.array([ # 1個目の画像 [[[ 0, 0, 255, 0, 0, 255],[255, 0, 0, 255, 0, 0]], #赤成分 [[255, 0, 0, 255, 0, 0],[ 0, 255, 0, 0, 255, 0]], #緑成分 [[ 0, 255, 0, 0, 255, 0],[ 0, 0, 255, 0, 0, 255]]],#青成分 # 2個目の画像 [[[ 0, 255, 255, 0, 255, 255],[255, 255, 0, 255, 255, 0]], [[255, 0, 255, 255, 0, 255],[ 0, 255, 255, 0, 255, 255]], [[255, 255, 0, 255, 255, 0],[255, 0, 255, 255, 0, 255]]], # 3個目の画像 [[[ 0, 0, 0, 0, 0, 0],[255, 255, 255, 255, 255, 255]], [[ 0, 0, 0, 0, 0, 0],[255, 255, 255, 255, 255, 255]], [[ 0, 0, 0, 0, 0, 0],[255, 255, 255, 255, 255, 255]]], # 4個目の画像 [[[255, 255, 255, 255, 255, 255],[ 0, 0, 0, 0, 0, 0]], [[255, 255, 255, 255, 255, 255],[ 0, 0, 0, 0, 0, 0]], [[255, 255, 255, 255, 255, 255],[ 0, 0, 0, 0, 0, 0]]] ])
こちらもnp.shapeで各次元の要素数を確認してみます。channel firstになっていることが分かります。

2.データ構造の変換方法
np.transpose関数を使用することで非常に簡単に変換が可能です。
2.1.Channel last ⇒ Channel first
image_channel_first = np.transpose(image_channel_last , [0,3,1,2])
2.2.Channel first ⇒ Channel last
image_channel_last = np.transpose(image_channel_first , [0,2,3,1])