過去記事一覧
過去の記事についてまとめます。
1.画像データ分析
① 画像分析モデルの紹介
画像分析モデルの実装方法について。モデルの概要も記載しています。
- TensorflowによるEfficientnetの実装
- TensorflowによるViT(Vision Transformer)の実装
- TensorflowによるBiT(Big Transfer)の実装
② モデルの比較
画像分類モデルを試してみた結果。
③ 前処理
④ XAI(説明可能AI)
2.テーブルデータ
① 前処理
- 機械学習における不均衡データへの対処方法(Over Sampling, Under Sampling等)
- 縦持ちデータを横持ちデータに変換する方法(Pandas)
- 横持ちデータを縦持ちデータに変換する方法(Pandas)
- 縦持ちデータを横持ちデータに変換する方法(SQL)
- 横持ちデータを縦持ちデータに変換する方法(SQL)
- Pandasでグループ毎に過去データを集約する方法
② XAI(説明可能AI)
3.株価予測
① LightGBMを使用した株価分析
② 前処理
3.競馬予測
① データ入手
② 過去戦績に基づくレーティング
- 競馬のレーティングをしてみた(Elo Rating)
- 多人数対戦におけるレーティング方法(glicko2 rating systemを用いて)
- 競走馬をレーティングしてみた(Glicko2 Rating System)
4.分析環境の構築
5.再現性確保
6.マルチGPU学習
7.エラー対処
- ViTモデルロード時のエラー(ValueError: Unknown layer: ClassToken)について
- "Blas GEMM launch failed"の対処法
- KerasのCallback:ModelCheckpoint使用時のエラー「Error! hdf5file is not UTF-8 encoded」について
- pandas-datareaderで株価データを取得する際に日付を指定できない問題
- ImageDataGeneratorにおいてfeaturewise系のオプションがうまく機能しない問題
- タスクスケジューラで陥りやすいトラブル集
- Seleniumエラー:Element is not clickable at point (xxx, xxx)について
Pythonのf-stringsを使ったPandas.DataFrameの列名の動的設定
変数を使用してPandas.DataFrameの列名を動的に設定する方法についてまとめます。 Pythonにはフォーマット済み文字列リテラル(f-strings)という記法が存在するのですが、今回はそれを使用します。
1.フォーマット済み文字列リテラル(f-strings)とは
文字列の中に変数や式の値を埋め込む手法です。例を見た方が早いので、以下に例示します。
name = 'Tarou' print(f'My name is {name}')
以下のように出力されます。
![]()
このように、文字列をf''で囲い、その中で変数や式を{}で囲うことで、変数や式の値を文字列に埋め込むことができます。 他にも出力する数字の桁数を指定したり色々とできます。詳細は以下、公式ドキュメントを参照ください。
2.DataFrameの列名の動的設定
フォーマット済み文字列リテラルはDataFrameにも使えます。これも例を見てみましょう。
import pandas as pd import plotly.express as px df = px.data.stocks() for i in range(1,4): df[f'GOOG_{i}'] = df['GOOG'].shift(i) display(df.head())

こんな感じでラグ変数の変数名を設定するときに使うことができます。その他、変数の掛け合わせ等様々な用途でフォーマット済み文字列リテラルは使えます。
pandasでデータ抽出する際の速度の比較(loc対query)
Pandas Dataframeに対して、locで抽出した方が良いのか、queryで抽出した方が良いのか。 可読性はqueryの方が良さそうですが、今回は性能面で比較してみようと思います。
1.データダウンロード
データはsklearnの「カリフォルニア住宅価格」を使用しました。
import pandas as pd from sklearn import datasets df = datasets.fetch_california_housing(as_frame=True).frame
2.処理時間計測
locとqueryそれぞれで%%timeitを使用して実行時間を計測します。
%%timeit -n 100 df.loc[(df['MedInc']>2.5) & (df['MedInc']<5)]
![]()
%%timeit -n 100 df.query('2.5<MedInc<5')
![]()
3.結果
結果はlocの方が倍ぐらい早いようでした。 複雑な条件になる場合はqueryの方が可読性が高いので、何度も呼び出さない場合はqueryでも良いと思いますが、速度を重視する場合はlocの方が良さそうです。
foliumを使ってハザードマップを重ねる
1.概要
Pythonの地図ライブラリ「folium」を使ってハザードマップを重ね合わせたいと思います。
ハザードマップは国土交通省国土地理院が公開しているのですが、APIも公開しているので、色々自分でカスタマイズすることもできます。ハザードマップAPIについては以下にまとまってます。
ハザードマップポータルサイト
地図のベースはfoliumを使用します。FoliumはLeaflet.jsライブラリをPythonで元々はJavascriptで作られたライブラリです。サイトとかを作るならLeaflet.jsの方が便利だと思います。
foliumを使うことで、簡単に地図上にマーカー、ライン、ポリゴンなどの地理情報を表示し、これらの要素にカスタマイズしたポップアップ情報を追加することができます。また、地図のズーム、位置、スタイルを制御できます。
GitHub - python-visualization/folium: Python Data. Leaflet.js Maps.
2.foliumについて
まずはfoliumから簡単に触ってみます。
import pandas as pd import folium latlons = ['35.658581', '139.745433'] # 東京タワーの緯度経度 fmap = folium.Map( location=latlons, tiles = "OpenStreetMap", zoom_start = 15, width = 500, height = 500 ) folium.Marker(latlons, popup="東京タワー").add_to(fmap) fmap
上記を実行すると以下のような地図が表示されます。
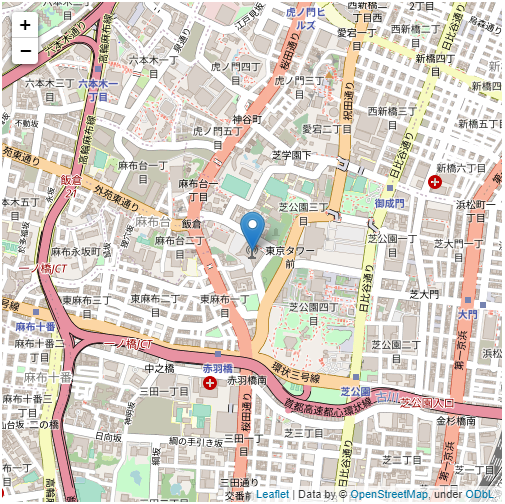
地図情報はOpenStreetMapというものを使用しています。GoogleMapを使うことも可能ですが、OpenStreetMapは無料なので、個人的にはこちらの方が好きです。 東京タワーの緯度経度情報をインプットに地図を表示しています。少し調べると住所から緯度経度情報を取得する方法も色々あるので、組み合わせてみても良いと思います。
3.ハザードマップを重ねてみる
次にハザードマップを重ねてみようと思います。
import pandas as pd import folium latlons = ['35.658581', '139.745433'] # 東京タワーの緯度経度 fmap = folium.Map( location=latlons, tiles = "OpenStreetMap", zoom_start = 15, width = 500, height = 500 ) folium.Marker(latlons, popup="東京タワー").add_to(fmap) fmap = add_tile_layer( fmap=fmap, tiles='https://disaportaldata.gsi.go.jp/raster/05_dosekiryukeikaikuiki/{z}/{x}/{y}.png', name='土砂災害警戒区域(土石流)' ) fmap = add_tile_layer( fmap=fmap, tiles='https://disaportaldata.gsi.go.jp/raster/01_flood_l2_shinsuishin_data/{z}/{x}/{y}.png', name='洪水浸水想定区域(想定最大規模)' ) fmap = add_tile_layer( fmap=fmap, tiles='https://disaportaldata.gsi.go.jp/raster/04_tsunami_newlegend_data/{z}/{x}/{y}.png', name='津波浸水想定' ) folium.LayerControl().add_to(fmap) fmap

国土地理院の公開するAPIから土石流、洪水、津波に関するハザードマップを呼び出してます。 LayerControlで重ねたハザードマップのレイヤーを消したり表示したりするコントロールを付与してます。 東京タワー周辺、、結構赤くなってますね。。
他にも公開されている情報はたくさんあるので、色々組み合わせてみると面白いかもしれません。
Pythonで株価データや金融データを取得する方法(pandas_datareader)
pandas-datareaderというpythonライブラリを使用して株価データや金融データを取得する方法についてまとめます。pandas-datareaderとはウェブ上の様々なデータソースにアクセスするライブラリです。今回は以下にアクセスします。
| アクセス先 | 概要 |
|---|---|
| Stooq | ポーランドのサイトで日本の株価データも取り扱っている。 |
| St.Louis FED (FRED) | セントルイス連邦準備銀行の公開している経済統計データ集。 株価データは取り扱っていない。 |
上記以外のデータソースは以下にまとまっています。
Data Readers — pandas-datareader v0.10.0 documentation
1.pandas-datareaderの使用方法
① インストール
pipコマンドを使用して以下の通りインストール。
pip install pandas-datareader
② Stooqからデータ取得
以下コードでStooqからデンソーの株価データを取得します。
# ライブラリのインポート import pandas_datareader.stooq as web from datetime import datetime # データ取得期間の設定 st = datetime(2015, 1, 1) ed = datetime(2020, 1, 1) # 株価価格等の取得 lst1=['6902.JP', #デンソー ] stooq = web.StooqDailyReader(lst1,start=st,end=ed).read() display(stooq.head())
<出力結果>

③ FREDからデータ取得
次にFREDからは株価以外の経済統計データを取得してみます。
試しにResidential Property Prices for Japanを取得してみます。
# ライブラリのインポート import pandas_datareader.fred as web from datetime import datetime # データ取得期間の設定 st = datetime(2015, 1, 1) ed = datetime(2020, 1, 1) # Residential Property Prices for Japanを取得 fred = web.FredReader('QJPN368BIS',start=st,end=ed).read() display(fred.head())
<出力結果>

Seleniumエラー:Element is not clickable at point (xxx, xxx)について
Selenium使用時に「Element is not clickable at point (xxx, xxx)」というエラーが出て色々調べたので、その内容についてまとめます。
1.結論
最初に結論だけ述べると、、
- エラー原因:画面外のelementを操作しようとしたため
- 解決方法:対象のelementまでSeleniumでスクロールする
2.事象再現
まずは適当にSeleniumを使って事象を再現してみます。
#モジュールのインポート import glob import datetime import time from selenium import webdriver from selenium.webdriver.common.by import By # ブラウザ起動 driver = webdriver.Chrome() driver.maximize_window() # アクセスするURL TARGET_URL = "https://suumo.jp/chintai/tokyo/ensen/" # 対象サイトへアクセス driver.get(TARGET_URL) time.sleep(2) #チェックボックスをクリック elements = driver.find_elements(By.CLASS_NAME, 'js-fr-checkSingle') elements[10].click() elements[30].click()
試していただければ分かると思いますが、実はelement[10].click()をコメントアウトすると、element[30]が画面外にあるボタンであるにも関わらず、エラーは起きないです。つまり、より詳細な原因としては、「一つ目のボタンを選択した状態で、画面外のボタンを操作しようとするとエラーになる」ようです。
3.解決方法
解決するために、Seleniumを使って画面スクロールします。
#element[30]が画面の真ん中らへんに来るように調整 window_size = driver.get_window_size() loc_y = elements[30].location['y'] if loc_y < window_size['height']/2: scroll_y = 0 else: scroll_y = loc_y - window_size['height']/2 driver.execute_script(f"window.scrollBy(0, {scroll_y});") elements[30].click()
以下のようにシンプルに対象elementまでスクロールしちゃってもいいのですが、WEBページによってはヘッダが邪魔で対象elementが隠れちゃうことがあります。隠れちゃうと同じエラーが出るので、少しめんどくさいですが、対象elementが真ん中らへんに来るように調整してます。スマートな実装があれば教えてほしいです。
4.ソース一式
#モジュールのインポート import glob import datetime import time from selenium import webdriver from selenium.webdriver.common.by import By # ブラウザ起動 driver = webdriver.Chrome() driver.maximize_window() # アクセスするURL TARGET_URL = "https://suumo.jp/chintai/tokyo/ensen/" # 対象サイトへアクセス driver.get(TARGET_URL) time.sleep(2) #チェックボックスをクリック elements = driver.find_elements(By.CLASS_NAME, 'js-fr-checkSingle') elements[10].click() #element[30]が画面の真ん中らへんに来るように調整 window_size = driver.get_window_size() loc_y = elements[30].location['y'] if loc_y < window_size['height']/2: scroll_y = 0 else: scroll_y = loc_y - window_size['height']/2 driver.execute_script(f"window.scrollBy(0, {scroll_y});") elements[30].click()
タスクスケジューラで陥りやすいトラブル集
タスクスケジューラ関連で個人的に躓いたポイントとその解決策についてまとめておきたいと思います。
1.予定時刻になってもタスクが実行されない問題
① 事象
以下のように繰り返し実行のタスクを作成するが、予定時刻になってもタスクが実行されないという事象。

予定時刻になっても、エラー表示も出ないままタスクが実行されず、勝手に「次回の実行時刻」が延期されます。エラーが出ないので、原因特定に時間がかかりました。
② 原因と対策
どうやら、これは「トリガー」設定に問題があったようです。以下のように、周期を[毎日]と設定したうえで、継続時間を[無期限]と設定するとタスクが正常に動作しないとのことです。Microsoft Japan Windows Technology Support Blogに情報があったので、詳しくはそちらを参照ください。

正確には以下のパターンのときに問題が発生するようです。
× : 毎日 / 毎週 / 毎月 + 繰り返し間隔の継続時間「無期限」
以下の場合はOKとのこと。
○ : 毎日 / 毎週 / 毎月 + 繰り返し間隔の継続時間「1 日間」など
○ : 1 回 + 繰り返し間隔の継続時間「無期限」
2.タスクは実行されるけどバッチが実行されない問題
① 事象
タスクスケジューラ上で「前回の実行時刻」が更新される(タスク自体は実行されている)のに、タスクから呼び出すバッチが起動しない事象。

これもエラーも出ず、ただただバッチが実行されないので、原因がなかなかわかりませんでした。
② 原因と対策
「操作の編集」の「開始(オプション)」が指定されていないのが問題らしいです。タスクスケジューラに関する記事を見ても「開始(オプション)」を必須と紹介する記事は少ないので、設定しなくても問題なく動くパターンもあるんだと思います。

競馬データのスクレイピング
netkeibaから競馬データをスクレイピングする方法についてまとめます。既に同様の記事は世にたくさん出回ってますが、少し改良して効率化してみました。
1.既出のスクレイピング方法の問題点
競馬データのスクレイピングで検索すると、以下のようなソースコードが多いと思います。
for i in range(1, 11): for j in range(1, 7): for k in range(1, 13): for l in range(1, 13): Base = "https://race.netkeiba.com/race/result.html?race_id=" race_id = "2019" + str(i).zfill(2) + str(j).zfill(2) + str(k).zfill(2) + str(l).zfill(2) url = Base + race_id '''------------------''' '''スクレイピング処理''' '''------------------'''
上記はrace_idを総当たりスクレイピングする方法ですが、残念ながら実際にはrace_idは飛び飛びで、存在しないrace_idがたくさんあります。よって無駄な検索をしていることになります。スクレイピング中にsleep処理を入れると思いますが、無駄な検索をするたびにsleepが入って、全体の処理時間が長引きます。
2.どうやって効率化するか
netkeibaには1日毎の開催レース一覧をまとめている以下のようなページがあります。
レース一覧 | 2023年5月20日 レース情報(JRA) - netkeiba.com
このページからrace_idの一覧を取得することで、実在するrace_idのリストを作成することができます。ここまで来たら後はあとはrace_idをキーにスクレイピングするだけです。
2.1.開催レース一覧ページからrace_idを取得する方法
開催レース一覧のページは動的にrace_idを設定しているようなので、beautifulsoupは使えません。こういうときはseleniumが効果的です。 以下のような実装でrace_idの一覧を取得できます。
import time from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By #selenium driverでブラウザ起動 def get_selenium_driver(url): options = Options() # ヘッドレスモードで実行する場合 options.add_argument("--headless") driver = webdriver.Chrome(options=options) # 取得先URLにアクセス driver.get(url) # コンテンツが描画されるまで待機 time.sleep(5) return driver #指定した開催日に開催されるレースのrace_id一覧を取得 def get_race_ids(kaisai_dates): race_ids = [] for kaisai_date in kaisai_dates: url = 'https://race.netkeiba.com/top/race_list.html?kaisai_date=' + kaisai_date driver = get_selenium_driver(url) elements = driver.find_elements(By.CLASS_NAME,"MyRace_List_Item") for element in elements: race_id = str(element.get_attribute('id')) race_id = race_id.replace("myrace_","") race_ids.append(race_id) return race_ids race_ids = get_race_ids(["20230528"])
上記で2023年5月28日に開催された全レースの全race_idをリストとして取得できます。
2.2.競馬のレース結果のスクレイピングする方法
これは他にサイトがたくさんあるので、今更紹介する必要はないと思いますが、一応まとめておきます。
from bs4 import BeautifulSoup import requests import pandas as pd def fetch_horse_datas(race_id, horse_datas): Base="https://race.netkeiba.com/race/result.html?race_id=" url = Base + race_id kaisai_year = int(race_id[:4]) request = requests.get(url) soup = BeautifulSoup(request.content, 'html.parser') horses = soup.find_all(class_='HorseList') data1 = soup.find(class_='RaceData01') data1 = data1.get_text().replace("/","").split() data2 = soup.find(class_='RaceData02') data2 = data2.select('span') data2 = [t.get_text(strip=True) for t in data2] data3 = soup.find(class_='Refundlink') data3 = str(data3) for horse in horses: horse_data = {} horse_data['start_time'] = data1[0] horse_data['race_type'] = data1[1] horse_data['ground'] = data1[2] horse_data['weather'] = data1[3] horse_data['gr_condition'] = data1[4] horse_data['place'] = data2[1] horse_data['rule'] = data2[3] horse_data['grade'] = data2[4] horse_data['sex'] = data2[5] horse_data['rule6'] = data2[6] horse_data['num_horse'] = data2[7] horse_data['year'] = kaisai_year horse_data['date'] = data3[data3.find("kaisai_date=")+12 : data3.find("kaisai_date=")+20] horse_data['race_id'] = race_id horse_data['rank'] = horse.find(class_='Rank').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['horse_number'] = horse.find(class_='Txt_C').find('div').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['horse_name'] = horse.find(class_='Horse_Name').find('a').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['seirei'] = horse.find(class_='Lgt_Txt Txt_C').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['jockey_weight'] = horse.find(class_='JockeyWeight').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['jockey_name'] = horse.find(class_='Jockey').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['race_time'] = horse.find(class_='RaceTime').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['popularity'] = horse.find(class_='OddsPeople').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['odds'] = horse.find(class_='Txt_R').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['passage'] = horse.find(class_='PassageRate').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['trainer'] = horse.find(class_='Trainer').find('a').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['weight'] = horse.find(class_='Weight').get_text().replace('\n','').replace(' ','').replace(' ','') horse_datas.append(horse_data) return horse_datas # レースデータをスクレイピング horse_datas = [] race_ids = get_race_ids(["20230528"]) for race_id in race_ids: try: # 出馬表を読み取る horse_datas = fetch_horse_datas(race_id, horse_datas) time.sleep(1.5) except Exception as e: print("error in race_id:",race_id,e) pass df = pd.DataFrame(horse_datas)
上記で2023年5月28日の全レース結果をスクレイピングできます。
3.ソースコード一式
以下にソースコード一式をまとめます。 以下では取得したい「年」を指定することで、その年の全レースデータ結果を取得できるようにしてます。
from bs4 import BeautifulSoup import requests import pandas as pd pd.set_option('display.max_columns', 150) pd.set_option('display.max_rows', 500) from tqdm import tqdm import time import datetime from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By # 今日の日付を取得 today = datetime.date.today() # 読み取り開始年、終了年 st_year = 2015 ed_year = today.year # 土日リストを取得 def get_weekends(): weekends = [] for target_year in range(st_year, ed_year+1): baseDate = datetime.date(target_year, 1, 1) days = (baseDate - datetime.date(target_year - 1, 1, 1)).days weekends.extend([(baseDate + datetime.timedelta(i)).strftime("%Y%m%d") for i in range(0, days) if (baseDate + datetime.timedelta(i)).weekday() >= 5]) return weekends def get_kaisai_dates(): weekends = get_weekends() return [weekend for weekend in weekends if (weekend<today.strftime("%Y%m%d"))] #selenium driverでブラウザ起動 def get_selenium_driver(url): options = Options() # ヘッドレスモードで実行する場合 options.add_argument("--headless") driver = webdriver.Chrome(options=options) # 取得先URLにアクセス driver.get(url) # コンテンツが描画されるまで待機 time.sleep(5) return driver #指定した開催日に開催されるレースのrace_id一覧を取得 def get_race_ids(kaisai_dates): race_ids = [] for kaisai_date in tqdm(kaisai_dates): url = 'https://race.netkeiba.com/top/race_list.html?kaisai_date=' + kaisai_date driver = get_selenium_driver(url) elements = driver.find_elements(By.CLASS_NAME,"MyRace_List_Item") for element in elements: race_id = str(element.get_attribute('id')) race_id = race_id.replace("myrace_","") race_ids.append(race_id) return race_ids def fetch_horse_datas(race_id, horse_datas): Base="https://race.netkeiba.com/race/result.html?race_id=" url = Base + race_id kaisai_year = int(race_id[:4]) request = requests.get(url) soup = BeautifulSoup(request.content, 'html.parser') horses = soup.find_all(class_='HorseList') data1 = soup.find(class_='RaceData01') data1 = data1.get_text().replace("/","").split() data2 = soup.find(class_='RaceData02') data2 = data2.select('span') data2 = [t.get_text(strip=True) for t in data2] data3 = soup.find(class_='Refundlink') data3 = str(data3) for horse in horses: horse_data = {} horse_data['start_time'] = data1[0] horse_data['race_type'] = data1[1] horse_data['ground'] = data1[2] horse_data['weather'] = data1[3] horse_data['gr_condition'] = data1[4] horse_data['place'] = data2[1] horse_data['rule'] = data2[3] horse_data['grade'] = data2[4] horse_data['sex'] = data2[5] horse_data['rule6'] = data2[6] horse_data['num_horse'] = data2[7] horse_data['year'] = kaisai_year horse_data['date'] = data3[data3.find("kaisai_date=")+12 : data3.find("kaisai_date=")+20] horse_data['race_id'] = race_id horse_data['rank'] = horse.find(class_='Rank').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['horse_number'] = horse.find(class_='Txt_C').find('div').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['horse_name'] = horse.find(class_='Horse_Name').find('a').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['seirei'] = horse.find(class_='Lgt_Txt Txt_C').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['jockey_weight'] = horse.find(class_='JockeyWeight').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['jockey_name'] = horse.find(class_='Jockey').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['race_time'] = horse.find(class_='RaceTime').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['popularity'] = horse.find(class_='OddsPeople').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['odds'] = horse.find(class_='Txt_R').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['passage'] = horse.find(class_='PassageRate').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['trainer'] = horse.find(class_='Trainer').find('a').get_text().replace('\n','').replace(' ','').replace(' ','') horse_data['weight'] = horse.find(class_='Weight').get_text().replace('\n','').replace(' ','').replace(' ','') horse_datas.append(horse_data) return horse_datas # レースデータをスクレイピング kaisai_dates = get_kaisai_dates() race_ids = get_race_ids(kaisai_dates) horse_datas = [] for race_id in tqdm(race_ids): try: # 出馬表を読み取る horse_datas = fetch_horse_datas(race_id, horse_datas) time.sleep(1.5) except Exception as e: print("error in race_id:",race_id,e) pass df = pd.DataFrame(horse_datas)